米兰体育官方网站 - MILAN
你的位置:米兰体育官方网站 - MILAN > 米兰资讯 >


连年来,基于大言语模子的多智能体系统(LLM-based Multi-Agent Systems, MAS)被平庸用于复杂推理任务。典型作念法是让多个 agent 平定生成并通过投票或申辩等机制团聚方案,从而在算术推理、知识推断与专科问答中培育准确率。
跟着 test-time compute(推理时缱绻)成为常见的智商培育妙技,一个当然的问题随之出现:MAS 是否能通过束缚增多 agent 数目而握续变强?直观上,这个设计似乎修复:肖似 ensemble 或 self-consistency 的「屡次采样 + 团聚」时时能提高隐敝正确谜底的概率。
来自上海交通大学、UC Berkeley、加州理工学院以及约翰・霍普金斯大学的鸠合征询论文 Understanding Agent Scaling in LLM-Based Multi-Agent Systems via Diversity 标明:多智能体系统「扩不动」的果然原因,并不是 Agent 不够多,而是信息冗余。 系统实验发现,单纯堆界限收益连忙衰败,而引入各样性不错显赫减速弥散、以更少的 Agent 获取更强的性能。

论文标题:Understanding Agent Scaling in LLM-Based Multi-Agent Systems via Diversity
GitHub 代码:https://github.com/SafeRL-Lab/Agent-Scaling
同质推广的失效:
界限带来的收益连忙弥散
论文最初平直磨练「增多 agent 数是否有用」。在同质竖立下,总共 agent 分享相似底座模子与系统请示(无 persona 各别,设立一致),继承两类常见伙同机制:
Vote:单轮平定生成后多半投票;
Debate:多轮交互后再给出最终谜底(交互 4 轮)。
仅改变 agent 数 N,在 7 个基准任务(GSM8K、ARC、Formal Logic、TruthfulQA、HellaSwag、WinoGrande、Pro Medicine)上评估。

收尾在不同任务与模子上高度一致:当 N 从 1 增至 2 或 4 时,性能时时昭彰培育;但不息增多 N 后,准确率连忙参加平台期,边缘收益接近 0,部分竖立以至出现回落。这证实:在同质设立下,单纯堆叠更多 agent calls 并不可握续注入新的有用信息。
各样性带来的对照清闲:
少许异质 agent 胜过大界限同质系统
与同质推广的快速弥散酿成昭着对比的是,各样性设立下的实验收尾。论文进一步相比了两类系统:一类由统一模子屡次平定开动组成,另一类则由不同 backbone 模子或不同 persona prompt 组成。在匹配缱绻预算(固定总 agent calls)的前提下,异质系统在同预算下举座更高,而且在更大的 N 上仍能保握增益。
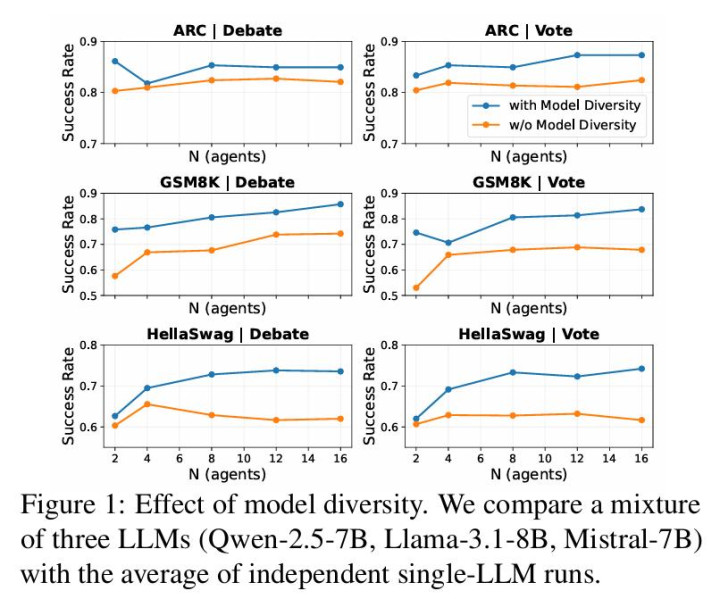
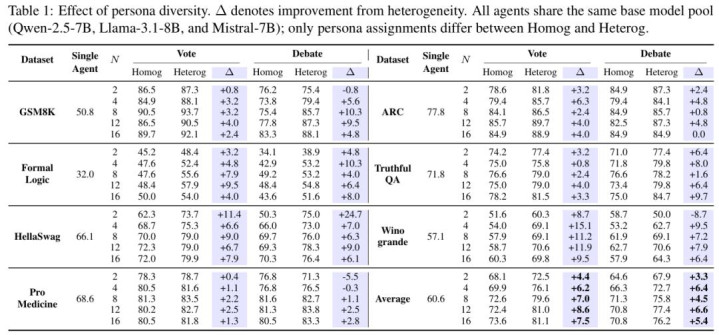
为了更系统地交融这一清闲,作家在实验中将各样性拆解为不同着手,包括 persona 各样性、模子各样性,以及二者结合的透彻各样性,并在斡旋竖立下进行对比。
在 GSM8K、ARC、HellaSwag、TruthfulQA 等七个基准任务上,作家系统相比了:
Agent 透彻一致(L1)
Agent Persona 各样性(L2)
Base Model 各样性(L3)
Persona各样性兼Base Model各样性(L4)
收尾清晰,每引入一层新的各样性,系统举座性能王人会显赫上移;其中,模子各样性和 persona 各样性各自王人具有平定孝敬,而二者结合时后果最为显赫。
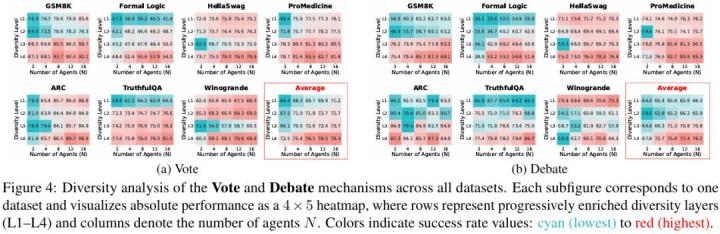
这一趋势在服从层面体现得尤为昭彰:在多个任务上,仅使用 2 个透彻异质的 agent,就不错达到以至跳跃 16 个同质 agent 的平均性能。
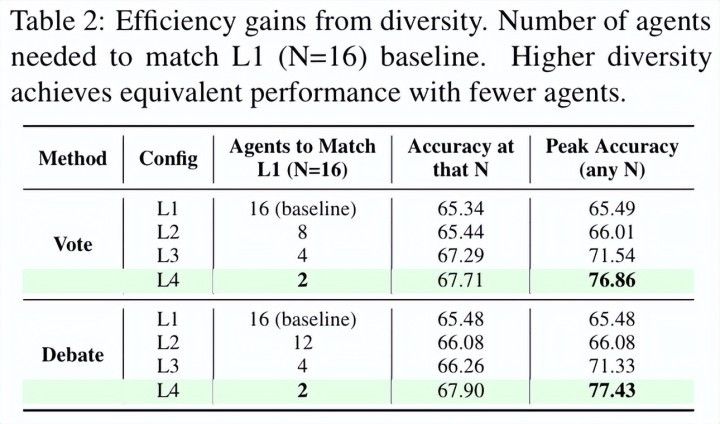
终了多智能体推广的不是界限
而是信息冗余
将这些实验收尾串联起来,论文在教育层面得出了一个清楚论断:多智能体系统的推广瓶颈并不来自 agent 数目不及,而来自 agent 输出之间的高度干系性。在同质设立下,多个 agent 时时沿着相似的推理旅途生成谜底,新增调用所带来的大多是重叠信息;而各样性的作用,在于引入互补视角,裁减输出冗余,米兰使系统好像在相似以至更小的缱绻预算下获取更多有用凭据。
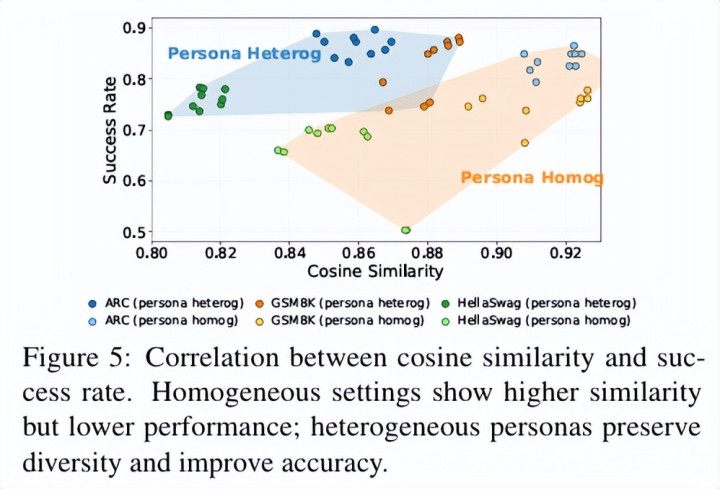
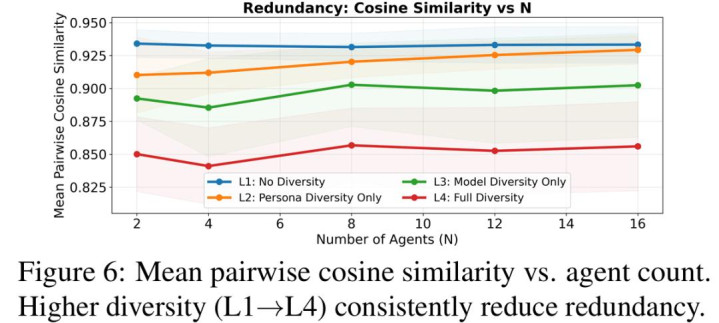
基于这一系列实验清闲,作家进一步冷漠信息论分析框架,引入「有用信息通说念」等观念,对「界限失效」与「各样性上风」给出斡旋证明。与其说这项责任冷漠了新的 agent 架构,不如说它明确指出:多智能体系统里果然稀缺的资源不是调用次数,而漫骂冗余的信息着手。
信息论视角:
性能由「有用信息」而非「调用次数」主导
作家研讨一个包含 N 个大模子智能体的多智能体系统,每个智能体具有自身设立,包括基座模子(backbone model)、系统请示词(system prompt)、变装设定(persona)与器具智商(tool access)。系统接受问题输入 X,按预设责任流实行若干次推理(记为 n 次),最终输出谜底。
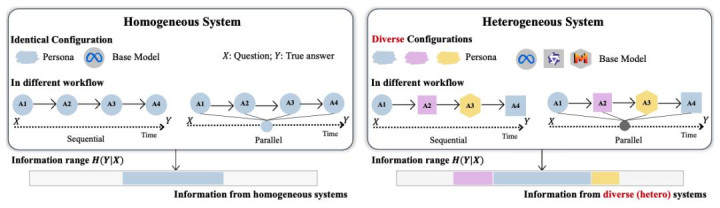
从信息论角度,得到正确谜底 Y 的告捷率并不浅显由 N 与 n 决定,而取决于系统好像提供若干对于 Y 的信息。作家用要求熵 H (Y|X) 描述任务的内在难度:在给定问题 X 的情况下,正确谜底 Y 仍然存在的剩余不细目性。
在同质设立下,即便新增智能体,时时也仅仅在相似推理旅途下重叠采样,因而对裁减不细目性匡助有限;
在异质设立下,新增智能体更可能引入新的推理旅途,与既有旅途互补,从而更有用地减少不细目性。
{jz:field.toptypename/}为描述这一各别,作家界说:

在该设定下,作家基于若干建模假定推导出一个近似模样,用于描述趋势而非精准瞻望。作家以为,系统可获取的有用信息量(并据此干系告捷率)主要受如下量主宰:
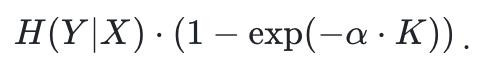
该收尾强调:影响系统性能的要害不在于 “智能体数目或推理次数”,而在于系统中有用信息通说念的数目 —— 也等于各样化所带来的非冗余信息界限。它也证明了为何履行中常见「边缘效益递减」:当有用信息通说念增长受限时,新增调用带来的有用信息增量会快速衰减。
作家还给出了在履行中臆想有用信息通说念 K 的身手,并在 GSM8K、ARC、Formal Logic、HellaSwag、WinoGrande、Pro Medicine 等数据集上考证:教育告捷率与表面瞻望总体吻合。
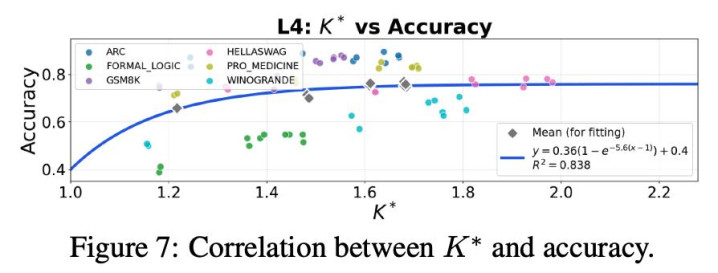
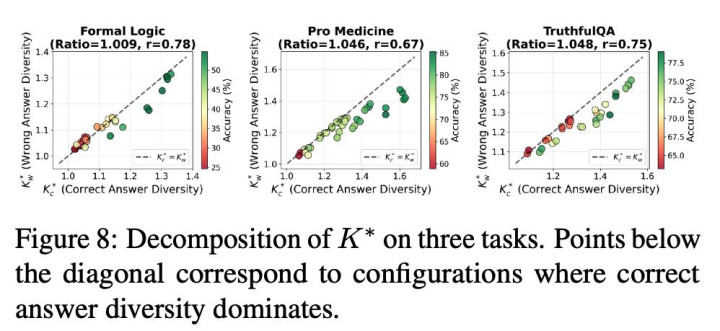
进一形状,作家将系统输出拆分为「正确推理旅途」与「造作推理旅途」,折柳估算其对应的有用信息通说念数目。实验一致标明:当正确推理旅途对应的有用信息通说念更多时,多智能体系统进展更好。这意味着系统设计不应盲目追求各样性本人,而应追求与任务干系的推理各样性 —— 即培育与正确推理干系的有用信息通说念数。
回来
论文的中枢教育论断是:多智能体推广的要害不在于把 N 作念大,而在于让新增调用带来新的有用凭据。只须输出高度干系,同质推广就会很快参加平台期;而各样性好像培育服从,是因为它更可能产生互补推理旅途。换句话说,多智能体系统里稀缺的不是调用次数,而漫骂冗余信息。
履行上不错用一个浅显门径调换推广:当增多 agent 主要带来「统一念念路的重叠」 时,应罢手堆同质数目,转而引入可控的异质性(身手互补的 persona、不同模子家眷、器具智商互补);唯有当这些改换确乎带来罕见增益时,再不息扩大界限。
 备案号:
备案号: